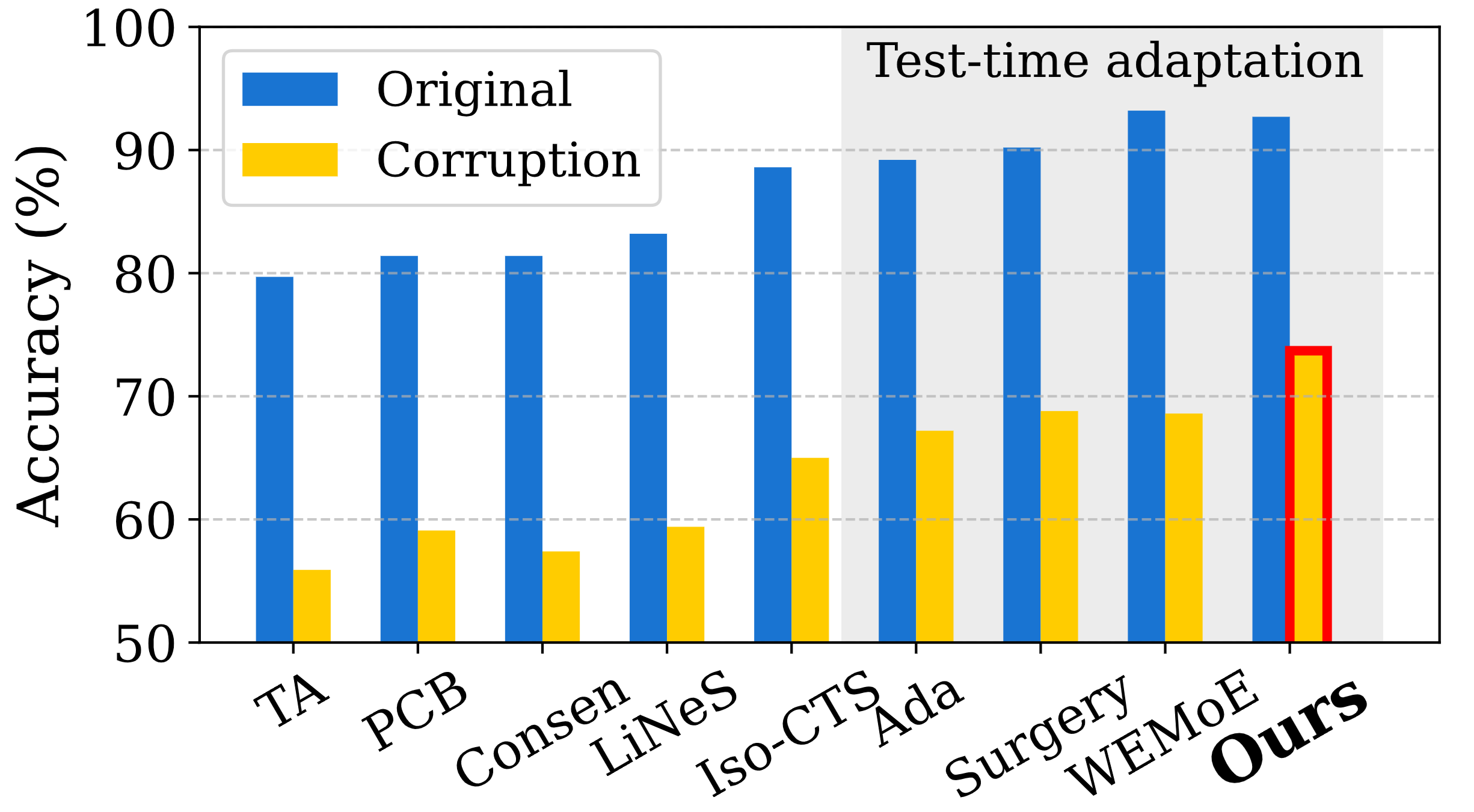
Model merging combines independently trained models into a single multi-task model. However, most existing approaches focus primarily on avoiding task interference. We argue that its greater potential lies in enabling task synergy, where tasks actively improve one another. We identify cross-task performance, defined by compatibility between encoders and predictors across tasks, as a key indicator of merge quality. We demonstrate that adapting only a single task-specific layer is sufficient to induce such synergy. This study proposes SyMerge, a lightweight framework that jointly optimizes merging coefficients and a single task-specific layer. We adopt an expert-guided self-labeling objective, providing stable supervision beyond entropy minimization. Intriguingly, we further show that SyMerge successfully merges models trained from different initializations, a regime where standard methods break down. Our minimalist yet principled method achieves state-of-the-art results across vision, dense prediction, and NLP benchmarks.